Sequence data
세상의 많은 데이터는 어떤 ‘sequence’를 이루고 있어요. 예를 들자면 이 글을 읽고 있는 여러분이 제가 적은 단어 단어를 순차적으로 이어서 비로서 이해할 수 있는 점이 있겠죠. 이런 데이터를 Sequence data라고 말해요. 때로는 이런 데이터를 Time Series(시계열) 데이터라고도 불러요.
일반적인 Neural Network와 Convolutional Neural Network는 이런 데이터를 다룸에 적합하지 않기 때문에 Recurrent, 순환하는 모델이 탄생했어요.
RNN
\[h_t = f_w(h_{t-1},x_t)\]\(h_t\) = 새로운 상태
\(f_w\) = 활성화 함수
\(h_{t-1}\) = 이전 상태
\(x_t\) = 입력 벡터
참고: 모든 네트워크에서 같은 함수와 같은 파라미터를 사용해요.
\(h_t = tanh(W_{hh}h_{t-1} + W_{xh}x_t)\)
\(y_t = W_{hy}h_t\)
Vanilla RNN
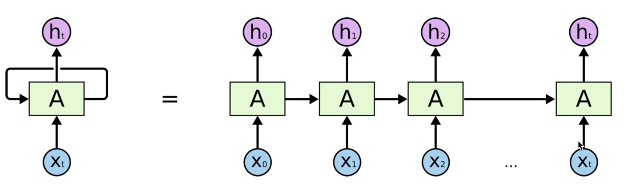
Various RNN
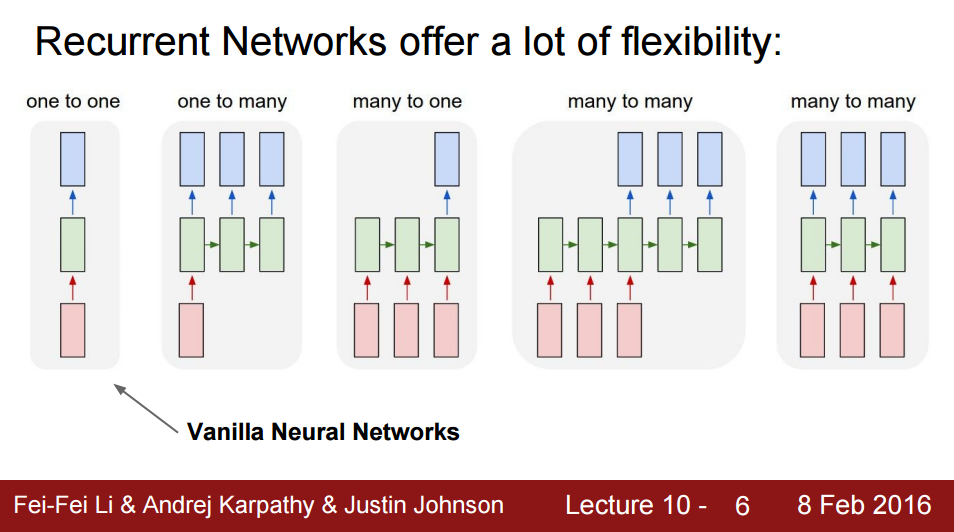
Language model
RNN이 곧잘 사용되는 분야로 자연어 처리가 있는데, 예를 들자면 Chrome 브라우저의 주소창에 ‘h’라고 입력했을 때, 사용자가 이전에 ‘hello’라고 입력한 적이 있다면 e를 예측하고, e를 입력했다면 l을 예측하는 식으로 예상되는 검색어를 보여주는 방법에 사용될 수 있어요.
만약 hello라는 단어를 데이터셋으로 사용한다면 우리는 겹치지 않는 [h,e,l,o]로 사전을 만들고 그에 해당하는 one-hot encoding을 통해 입력값을 줄 수 있어요.
1 0 0 0
0 1 0 0
0 0 1 0
0 0 0 1
h e l o
만약 저런 식으로 입력값을 주면 RNN에서는 어떤 처리과정을 거칠까요?
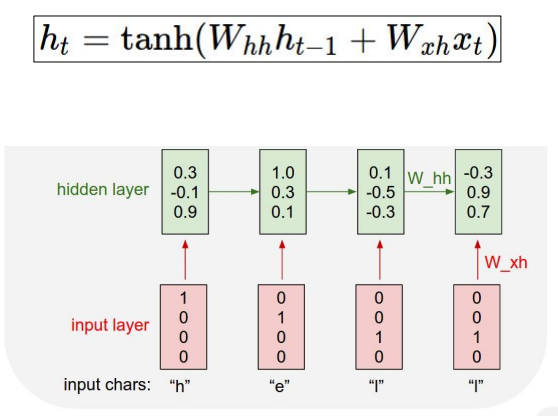
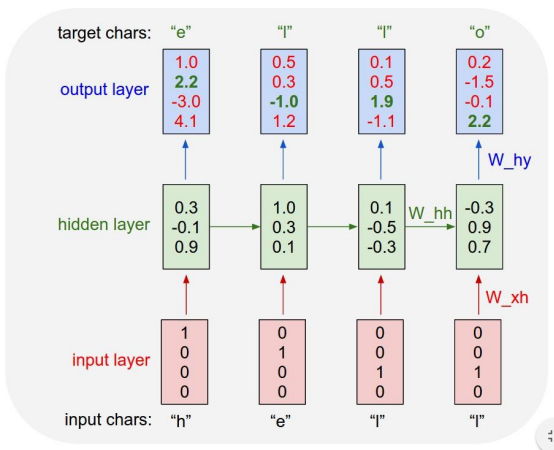
맨 처음에는 이전 state의 값을 전달받지 않기 때문에 \(tanh(0+W_{xh}x_t)\)의 과정을 거치고, 그 이후부터 이전 state의 값을 전달받아 연산해 값을 구해나가요.
은닉 계층에서의 계산이 끝난 경우 출력 계층에서는 \(y_t = W_{hy}h_t\) 공식을 통해 출력값을 뽑아내요.
RNN 응용
- 언어 모델
- 음성 인식
- 기계 번역
- 대화형 모델 / 질의 응답
- 이미지/영상 자막
- 이미지/음악.. 등 생성
RNN은 학습이 어렵다.
기본적인 RNN 모델을 사용하면 Vanishing Gradient 문제가 발생할 수 있기 때문에 학습을 용이하게 하기 위한 이런 변형모델들이 존재해요.
- Long Short Term Memory(LSTM)
- GRU
튜토리얼을 보고 공부해봐야겠어요.